
About Me
I am an Assistant Professor in the Department of Computer Engineering and an affiliated faculty member with Computer Science department. My research interests primarily revolve around general-purpose AI. Over the past few years, I have had the pleasure of working alongside a cohort of exceptionally bright and talented students who have accompanied me on this academic journey. Sometimes, they listen to me. I have a charming feline companion 🐈 that graces my life, Mr. Tiger, who brings a lot of joy to the family.
Research Interests
My research endeavors have been dedicated to the development of general intelligence for X tailored to address interdisciplinary challenges (e.g., autonomous driving, cancer diagnosis, and sustainable energy). Through these multidisciplinary investigations, I strive to contribute to the advancement of knowledge and the resolution of pressing issues across diverse disciplines (e.g., transportation, health care, and inertial confinement fusion). These endeavors have garnered support from National Science Foundation (NSF) and indurstial partners. By harnessing the power of AI, I aim to unravel complexities, devise innovative strategies, and ultimately make substantial contributions to the betterment of society. I am continuously looking for doctoral students to work with my research projects. If you want to develop awesome AI tools to address real-world problems, I think we need to talk 😄.
Research Projects
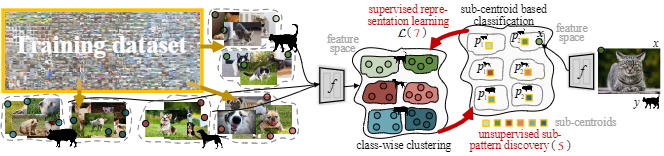
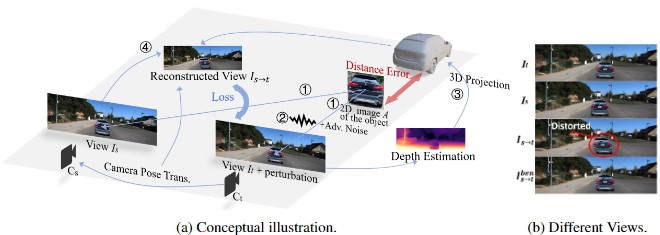

Services
- Area Chair: The Association for Computational Linguistics (ACL), 2026-
- Area Chair: The Conference on Computer Vision and Pattern Recognition (CVPR), 2023-
- Senior PC: The International Joint Conference on Artificial Intelligence (IJCAI), 2023-
- Senior PC: The Association for the Advancement of Artificial Intelligence (AAAI), 2023-
- Associate editor: IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2023-
- Associate editor: Neurocomputing, 2024-
- Associate editor: ACM Journal on Autonomous Transportation (JATS), 2023-
Publications
Xiang Zhang, Yiyang Liu, Runjia Zeng, Siyuan Qi, Qifan Wang, Dongfang Liu*, Cheng Han
ACL 2026Changyu Liu, Yiyang Liu, Taowen Wang, Qiao Zhuang, James Chenhao Liang, Wenhao Yang, Renjing Xu, Qifan Wang, Dongfang Liu*, Cheng Han
ACL 2026Tingxu Han, Wei Song, Ziqi Ding, Ziming Li, Chunrong Fang, Yuekang Li, Dongfang Liu, Zhenyu Chen, Zhenting Wang
ACL 2026Changyu Liu, James Chenhao Liang, Wenhao Yang, Yiming Cui, Jinghao Yang, Tianyang Wang, Qifan Wang, Dongfang Liu, Cheng Han
CVPR findings 2026Runjia Zeng, Qifan Wang, Qiang Guan, Ruixiang Tang, Lifu Huang, Zhenting Wang, XUELING ZHANG, Cheng Han, Dongfang Liu*
ICLR 2026Yanshu Li, Jianjiang Yang, Ziteng Yang, Bozheng Li, Hongyang He, Zhengtao Yao, Ligong Han, Yingjie Victor Chen, Songlin Fei, Dongfang Liu, Ruixiang Tang
AAAI 2026Runjia Zeng, James Chenhao Liang, Cheng Han, Zhiwen Cao, Jiahao Liu, Xiaojun Quan, Yingjie Victor Chen, Lifu Huang, Tong Geng, Qifan Wang, Dongfang Liu*
NeurIPS 2025Yijun Hu, Bing Fan, Xin Gu, Haiqing Ren, Dongfang Liu, Heng Fan, Libo Zhang
NeurIPS 2025Yiyang Liu, James Chenhao Liang, Heng Fan, Wenhao Yang, Yiming Cui, Xiaotian Han, Lifu Huang, Dongfang Liu, Qifan Wang, Cheng Han
NeurIPS 2025Runjia Zeng, Guangyan Sun, Qifan Wang, Tong Geng, Sohail Dianat, Xiaotian Han, Raghuveer Rao, Xueling Zhang, Cheng Han, Lifu Huang, Dongfang Liu*
EMNLP 2025Taowen Wang, Cheng Han, James Chenhao Liang, Wenhao Yang, Dongfang Liu*, Luna Xinyu Zhang, Qifan Wang, Jiebo Luo, Ruixiang Tang
ICCV 2025Guangyan Sun, Mingyu Jin, Zhenting Wang, Cheng-Long Wang, Siqi Ma, Qifan Wang, Tong Geng, Ying Nian Wu, Yongfeng Zhang, Dongfang Liu*
ICLR 2025Yiyang Liu, James Chenhao Liang, Ruixiang Tang, Yugyung Lee, MAJID RABBANI, Sohail Dianat, Raghuveer Rao, Lifu Huang, Dongfang Liu, Qifan Wang, Cheng Han
ICLR 2025Ruibing Song, Chuan Liu, Chunshu Wu, Ang Li, Dongfang Liu, Ying Nian Wu, Tong Geng
ICLR 2025Chuan Liu, Chunshu Wu, shihui cao, Mingkai Chen, James Chenhao Liang, Ang Li, Michael Huang, Chuang Ren, Ying Nian Wu, Dongfang Liu, Tong Geng
ICLR 2025Runjia Zeng, Cheng Han, Qifan Wang, Chunshu Wu, Tong Geng, Lifu Huang, Ying Nian Wu, Dongfang Liu*
NeurIPS 2024Yawen Lu, Cheng Han, Qifan Wang, Heng Fan, Zhaodan Kong, Dongfang Liu*, Yingjie Chen
TPAMI 2024Jiamian Wang, Pichao Wang, Dongfang Liu, Qiang Guan, Sohail Dianat, Majid Rabbani, Raghuveer Rao, Zhiqiang Tao.
NeurIPS 2024Taowen Wang, Yiyang Liu, James Chenhao Liang, junhan zhao, Yiming Cui, Yuning Mao, Shaoliang Nie, Jiahao Liu, Fuli Feng, Zenglin Xu, Cheng Han, Lifu Huang, Qifan Wang, Dongfang Liu*
EMNLP 2024Li Yang, Qifan Wang, Jianfeng Chi, Jiahao Liu, Jingang Wang, Fuli Feng, Zenglin Xu, Yi Fang, Lifu Huang, Dongfang Liu*
EMNLP 2024Xiaoyi Yang, Yuxing Wang, Tahmid Rafi, Dongfang Liu, Xiaoyin Wang, Xueling Zhang
ISSTA 2024Liqi Yan, Qifan Wang, Junhan Zhao, Qiang Guan, Zheng Tang, Jianhui Zhang, Dongfang Liu*
ECCV 2024Cheng Han, Qifan Wang, Sohail Dianat, Majid Rabbani, Raghuveer Rao, Yi Fang, Qiang Guan, Lifu Huang, Dongfang Liu*
ECCV 2024Shaohua Dong, Yunhe Feng, Qing Yang, Yan Huang, Dongfang Liu, Heng Fan
IROS 2024Zhiyuan Cheng, Cheng Han, James Liang, Qifan Wang, Xiangyu Zhang, Dongfang Liu*
TPAMI 2024Cheng Han, Yawen Lu, Guohao Sun, James Chenhao Liang, Zhiwen Cao, Qifan Wang, Qiang Guan, Sohail Dianat, Raghuveer Rao, Tong Geng, Zhiqiang Tao, Dongfang Liu*
ICML 2024Zhiyuan Cheng, Zhaoyi Liu, Tengda Guo, Shiwei Feng, Dongfang Liu, Mingjie Tang, Xiangyu Zhang
ICML 2024Pouya Haghi, Cheng Tan, Anqi Guo, Chunshu Wu, Dongfang Liu, Ang Li, Anthony Skjellum, Tong Geng, Martin Herbordt
ICS 2024Jiamian Wang, Guohao Sun, Pichao Wang, Dongfang Liu, Sohail Dianat, Majid Rabbani, Raghuveer Rao, Zhiqiang Tao
CVPR 2024Yawen Lu, Dongfang Liu*, Qifan Wang, Cheng Han, Yiming Cui, Zhiwen Cao, Xueling Zhang, Yingjie Victor Chen, Heng Fan
CVPR 2024Cheng Han, James Chenhao Liang, Qifan Wang, MAJID RABBANI, Sohail Dianat, Raghuveer Rao, YingNian Wu, Dongfang Liu*
ICLR 2024Cheng Han, Qifan Wang, Yiming Cui, Wenguan Wang, Lifu Huang, Siyuan Qi, Dongfang Liu*
ICLR 2024Zhiyuan Cheng, Hongjun Choi, Shiwei Feng, James Chenhao Liang, Guanhong Tao, Dongfang Liu, Michael Zuzak, Xiangyu Zhang
ICLR 2024Zheyun Qin, Xiankai Lu, Dongfang Liu, Xiushan Nie, Yilong Yin, Jianbing Shen, Alexander C. Loui.
TIP 2023Qifan Wang, Yuning Mao, Jingang Wang, Hanchao Yu, Shaoliang Nie, Sinong Wang, Fuli Feng, Lifu Huang, Xiaojun Quan, Zenglin Xu, Dongfang Liu*.
EMNLP 2023James Liang, Yiming Cui, Qifan Wang, Tong Geng, Wenguan Wang, Dongfang Liu*.
NeurIPS 2023Cheng Han, Qifan Wang, Yiming Cui, Zhiwen Cao, Wenguan Wang, Siyuan Qi, Dongfang Liu*.
ICCV 2023Dongfang Liu*, James Liang, Tony Geng, Alexander Loui, Tianfei Zhou.
TIP 2023James Liang, Tianfei Zhou, Dongfang Liu*, Wenguan Wang.
ICML 2023Li Yang, Qifan Wang, Jingang Wang, Xiaojun Quan, Fuli Feng, Yu Chen, Madian Khabsa, Sinong Wang, Zenglin Xu, Dongfang Liu*.
ACL 2023Qifan Wang, Jingang Wang, Xiaojun Quan, Fuli Feng, Zenglin Xu, Shaoliang Nie, Sinong Wang, Madian Khabsa, Hamed Firooz, Dongfang Liu*.
ACL 2023Liqi Yan, Cheng Han, Zenglin Xu, Dongfang Liu*, Qifan Wang.
IJCAI 2023Yawen Lu, Qifan Wang, Siqi Ma, Tong Geng, Yingjie Victor Chen, Huaijin Chen, Dongfang Liu*.
CVPR 2023The template of this website is designed by templatemo.